Removing top rows is straightforward from within the Power Query user interface and if done only upon one source. The problem arises when we need to remove a dynamic number of top rows from multiple sources and we don’t know the exact number of redundant rows in each source.
In this blog post, we will see how we can resolve this problem with M and remove top rows dynamically.
Different Source structures
In the picture below, we can see different structures of 3 .xlsx files that contain data for different regions.
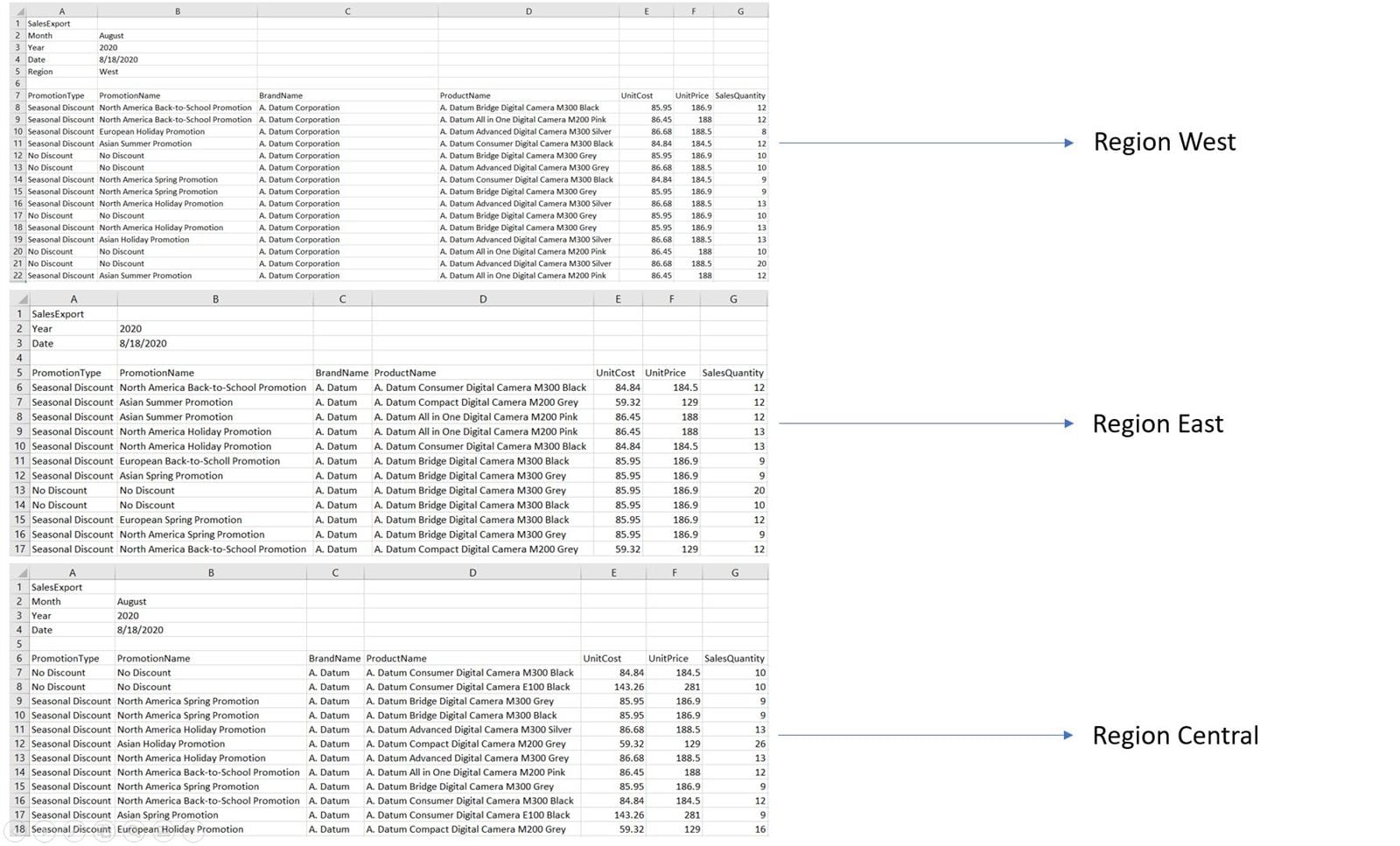
The problem is that for each file, the number of rows that we would need to remove to get to the table data is different. In the West region, we need to remove top 6 rows, in the East 4, and in the Central region 5 rows.
To get all 3 tables into a proper table structure for analysis, we would need to dynamically remove top rows to return only table data that resides below “junk” information in the first 4-6 rows, depending on the source file.
Using M Function with Dinamic Argument
We will resolve the problem described by creating a custom M function that will use a dynamic number in the second argument of Table.Skip() function.
The Table.Skip() is an M function that is written for us by the Power Query engine when we remove top rows in the user interface. The first argument of the function is the table from which we want to remove top rows, and the second argument is the number of rows to remove (or to skip). The second argument is the one that we will need to modify to make it dynamic for different regions.
Let’s start creating this function by first modifying the West region query as an example upon which we will create a custom function.
We will take the West Excel file inside of the Power Query editor. The first step in creating a dynamic solution is to create an index column starting from 1.
#"Added Index" = Table.AddIndexColumn(Sheet1_Sheet, "Index", 1, 1, Int64.Type)
Anchor Value
Next, we will filter out the first column to contain “PromotionType” text, which is the anchor value that will be present in every Excel file. Before filtering the column, we need to change its type to text because if any other type of value appears in the filtered column (e.g. date) it might break our query. After filtering we will receive a single row containing the Index of the filtered anchor value. We could have achieved the same by filtering another column, for example, Column2 with “PromotionName” text. The important thing is to choose one column with its corresponding anchor value that is the header of the table we want to extract. That anchor value for Column1 is PromotionType, Column2 PromotionName, and so on.

After getting this row, we can use the row and record syntax to drill into the Index column. To achieve that, we will add {0}[Index] at the end of the filtered rows step formula. This will get us the first row ({0} syntax ), and “Index” column with the [Index] syntax. We could have achieved the same via Power Query user interface by right-clicking on the value 7 in the Index column and choosing the Drill Down option.
Remember, row index starts at 0 in Power Query.
The M code so far:
let
Source = Excel.Workbook(File.Contents("C:\Users\KristianRadoš\Desktop\RegionalSales\West.xlsx"), null, true),
Sheet1_Sheet = Source{[Item="Sheet1",Kind="Sheet"]}[Data],
#"Added Index" = Table.AddIndexColumn(Sheet1_Sheet, "Index", 1, 1, Int64.Type),
#"Changed Type" = Table.TransformColumnTypes(#"Added Index",{{"Column1", type text}}),
#"Filtered Rows" = Table.SelectRows(#"Changed Type", each ([Column1] = "PromotionType"))
in
#"Filtered Rows"
The result of this query is number 7, which is the number of the row where the headers of the table reside. This means we need to skip 6 rows from the sheet to get to the row with the table headers.
Creating a Function
The next step is to create a function out of the previous query. To do it, we will modify the existing query and introduce a function with one variable called InputTable.
(InputTable as table) as table=>
let
IndexNumber =
let
#"Added Index" = Table.AddIndexColumn(InputTable, "Index", 1, 1, Int64.Type),
#"Changed Type" = Table.TransformColumnTypes(#"Added Index",{{"Column1", type text}}),
#"Filtered Rows" = Table.SelectRows (#"Added Index", each ([Column1] = "PromotionType")){0}[Index]
in
#"Filtered Rows",
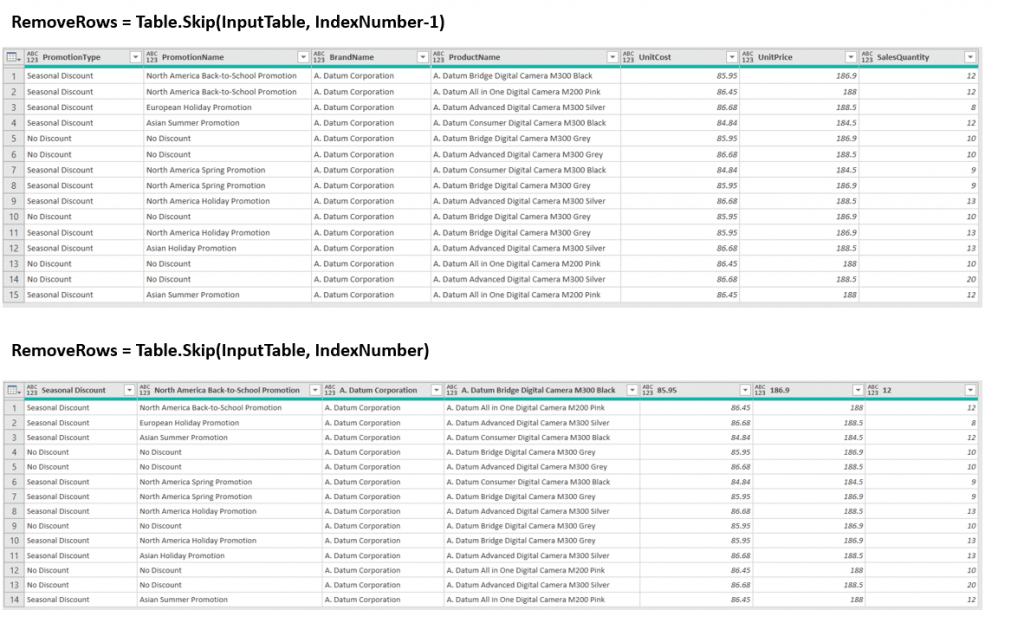
RemoveRows = Table.Skip(InputTable, IndexNumber-1),
PromoteHeaders = Table.PromoteHeaders(RemoveRows)
in
PromoteHeaders
In this function, we have the first step which is a nested let expression that will dynamically return the number of rows to skip depending on which row does anchor value appear in. The inner let contains two steps we described before to get a row in which the anchor value resides and get the index number of that row. That is row number 7 for the West region (the number will change for other regions). The RemoveRows step is about using Table.Skip() function to remove rows from the original table (InputTable variable). The second argument of the Table.Skip() function (IndexNumber-1) is the number of rows to skip.
Why is there -1? If we filter out 7 rows from the West region, we will lose the table headers since they are in the 7th row of the table. Therefore, we need to filter out only 6 rows (7-1) and in the next step promote headers to get a proper table structure with correct column names. You can see the difference in the picture below. We could have also mitigated -1 by initially starting our index column from 0 instead of 1.
We will call our function FXRemoveTopRows. Now to test it, we will invoke the function on each of the three queries as an InputTable argument (Central, East, West).
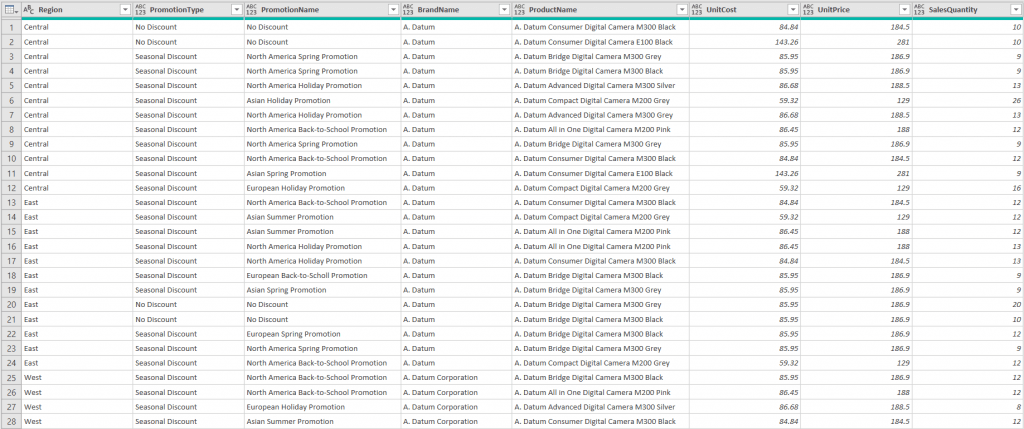
The result gives us cleaned tables.
To add even more power to this function, we can make small modifications to make it more robust. The shortcomings of this function are that you need to hardcode the anchor value as “PromotionType” and the column to filter as [Column1]. Also, in the #“Changed Type” step we are referencing a column by its name, which means that we always have to choose Column1.
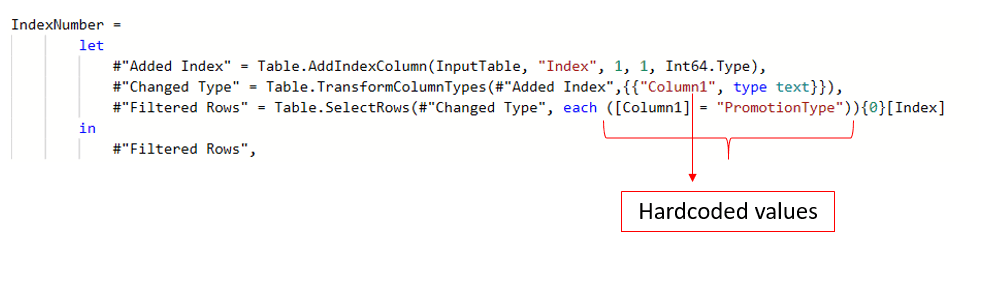
Another potential problem is that filtering in Power Query is case sensitive, so we need to write PromotionType correctly without missing uppercased letters.
To get around these problems, we can create additional two arguments in the function which will contain the column name and the anchor value and make this function even more dynamic.
The M Code For the Final Function:
(InputTable as table, ColumnName as text, AnchorValue as text) as table=>
let
IndexNumber =
let
#"Added Index" = Table.AddIndexColumn(InputTable, "Index", 1, 1, Int64.Type),
#"Changed Type" = Table.TransformColumnTypes(#"Added Index",{{ColumnName, type text}}),
#"Filtered Rows" = Table.SelectRows(#"Changed Type", each (Text.Lower(Record.Field(_, ColumnName)) = Text.Lower(AnchorValue))){0}[Index]
in
#"Filtered Rows",
RemoveRows = Table.Skip(InputTable, IndexNumber-1),
PromoteHeaders = Table.PromoteHeaders(RemoveRows)
in
PromoteHeaders
Now, let’s explain the M code for the function above.
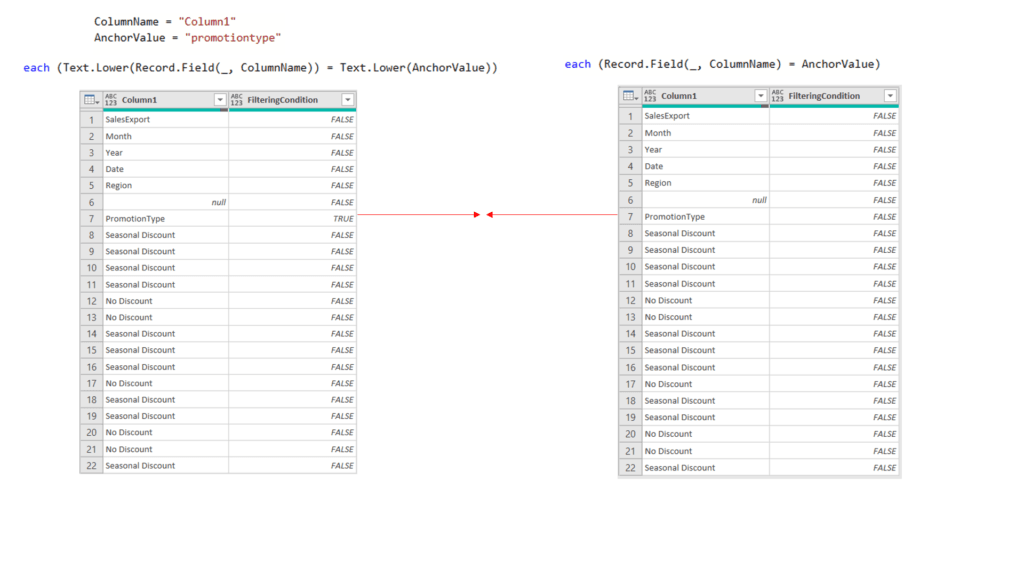
In the #“Changed Type” step, we have referenced ColumnName function parameter rather than the hardcoded Column1. This means that we can provide, for example Column5, and the function will change Column5 type to text.
Record.Field(_, ColumnName) is the replacement for [Column1] in the Table.SelectRows() function.
The syntax of the Record.Field(): Record.Field(record as record, field as text)
Since we are inside of the each syntax, and each represents iteration row by row, the underscore variable (_) is a record type of value holding all values from the current row of the iteration. From that record, we are providing the ColumnName dynamically as an argument of the outer function. This will filter out only the rows of the table with the AnchorValue, which is also a value that we specify as an argument in the function call.
Text.Lower(), which is added in front of Record.Field() and AnchorValue is here to make both sides lowercased, so that we avoid case sensitivity which is native to Power Query.
Testing Results
We will run the test on all three regions by invoking the function on each table.
The syntax example: FXRemoveTopRows(East, “Column1”, “promotiontype”).
The result:
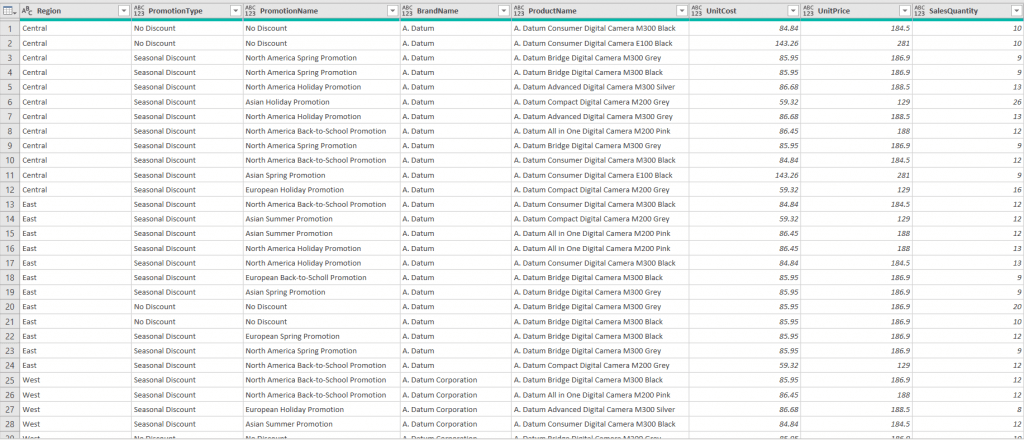
Our tables are properly cleaned and ready to be further modified or loaded into the data model.
The last solution provides a great way to remove top rows from any table structure by defining three arguments that enter the function:
- The input table that needs to be transformed,
- The column name in which the anchor value resides,
- The anchor value which will later become the header of the cleaned table.
In case you have any questions, please feel free to post them down below!
Very good the article
Try this approach: https://www.ehansalytics.com/blog/2020/11/6/use-listpositionof-to-find-the-first-row-of-data-in-an-excel-file
Hi Lluis, thanks for your input. Nice use of List.PositionOf() function. This shows how you can achieve the same results with multiple M approaches, which is the beauty of this language.