In this blog, we will explain nested functions in Power Query, as well as how to optimize these functions with buffering. By using nested functions and buffering, we will combine most of the advanced M coding.
Business Case
We will demonstrate the business problem we want to solve with the following snapshot from the Contoso database.
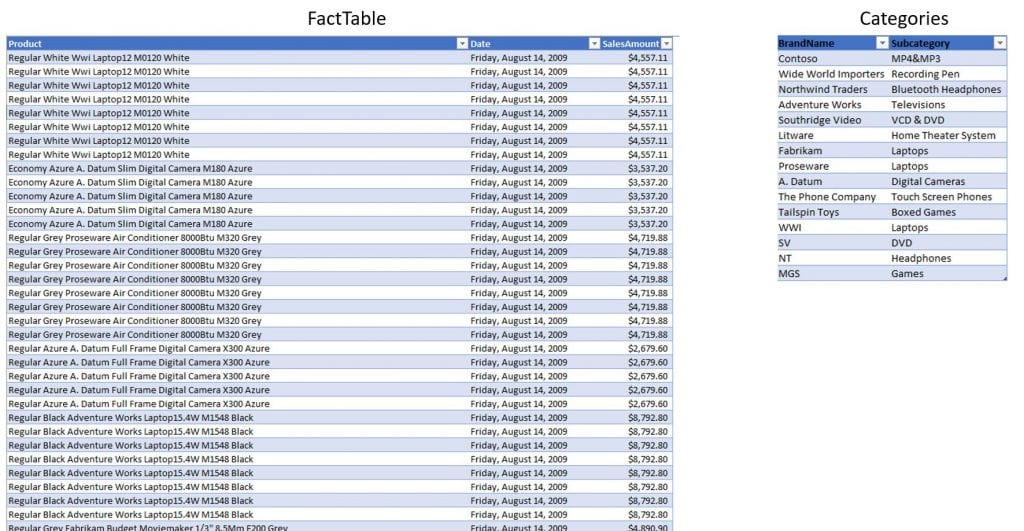
As we can see in the tables above, there is no key column on which we could do the merging, but we still need to merge those 2 tables. We are going to merge them using “partial match”, meaning we will search for keywords from the Categoriestable in each name in the [Product] column of the FactSalestable.
Following is the M logic we will try to implement. For each product in the FactTable, we want to iterate through the Categoriestable and compare if the product name contains any of the brand keywords from the Categoriestable. If it does, then those rows of the Categoriestable should be kept in a nested table of the current outer row iteration (the one of the FactTable). (Image below)
I know that we can try fuzzy merging or other techniques, but I find the following technique best for explaining both eachkeyword and nested functions.
Each Keyword
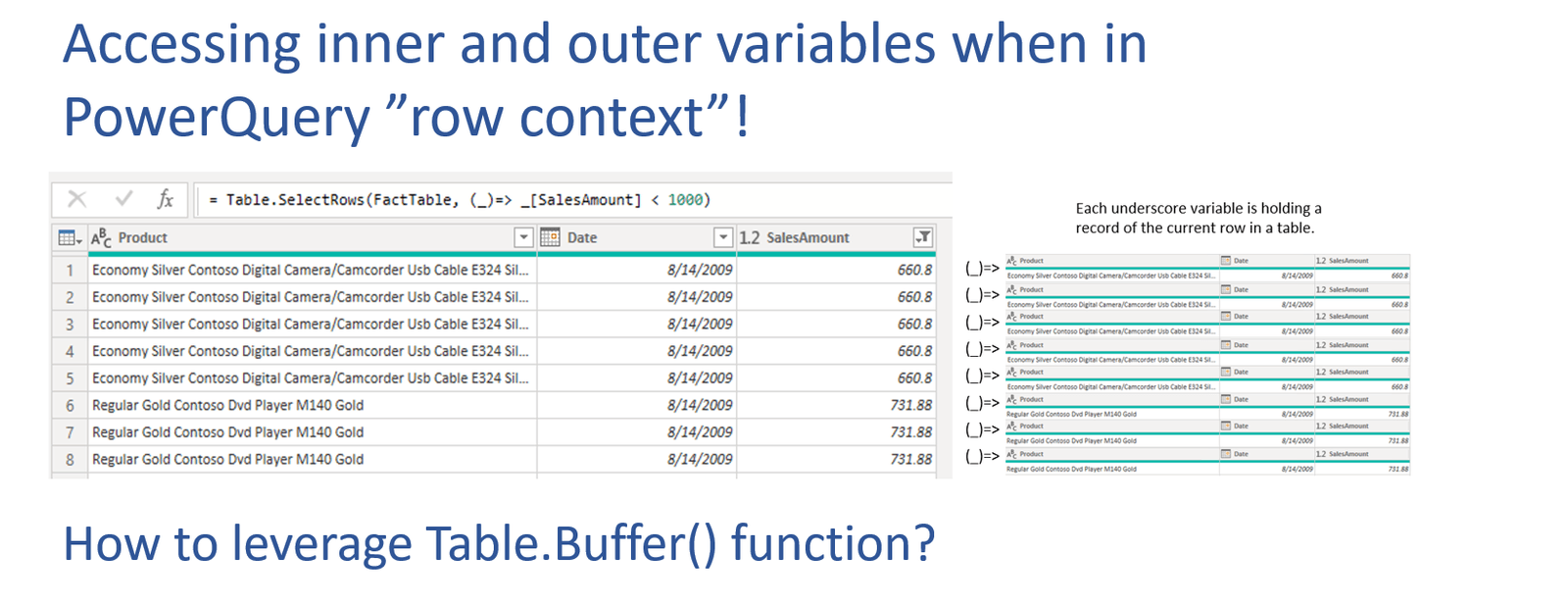
Before revealing the code for the partial search technique, let’s explain the eachkeyword. Let’s say that we want to filter the FactTable to only show products with [SalesAmount] <1000. We can use filter option from within the PowerQuery UI. Filtering will produce the following M code as shown in the formula bar in the picture below.
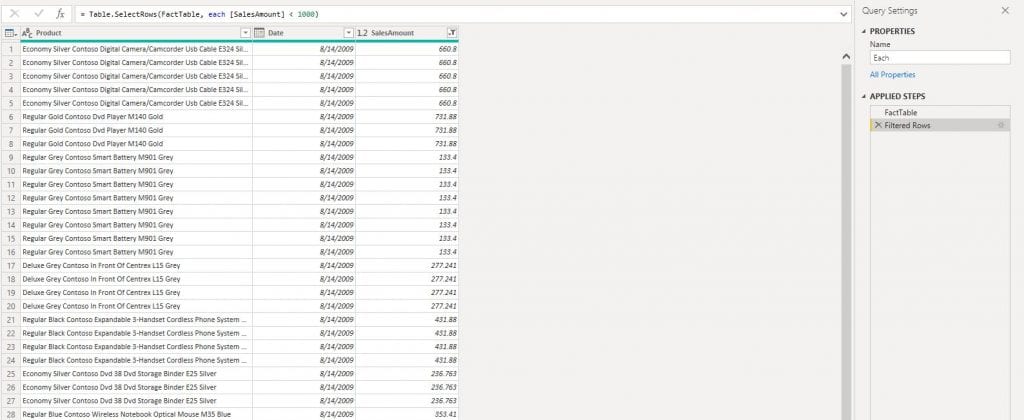
If we observe the M code of the step, we can see that it consist of Table.SelectRows() function which has 2 arguments. The first argument is the name of the table, and the second is the condition as a function. At the moment the second argument seems unclear, but we will soon demystify what it represents.
The keyword each represents the introduction of iteration. Table.SelectRows() is an “iterative” M function which creates a sort of a row context (similar to DAX row context) in which the same condition is compared for each row in the table. What we need to understand at this point is that eachkeyword is a sugar syntax for “Iterative function invoke”. If we remove the sugar syntax, the formula above becomes:
= Table.SelectRows(FactTable, (_)=> _[SalesAmount] < 1000)
This is how PowerQuery reads eachkeyword.
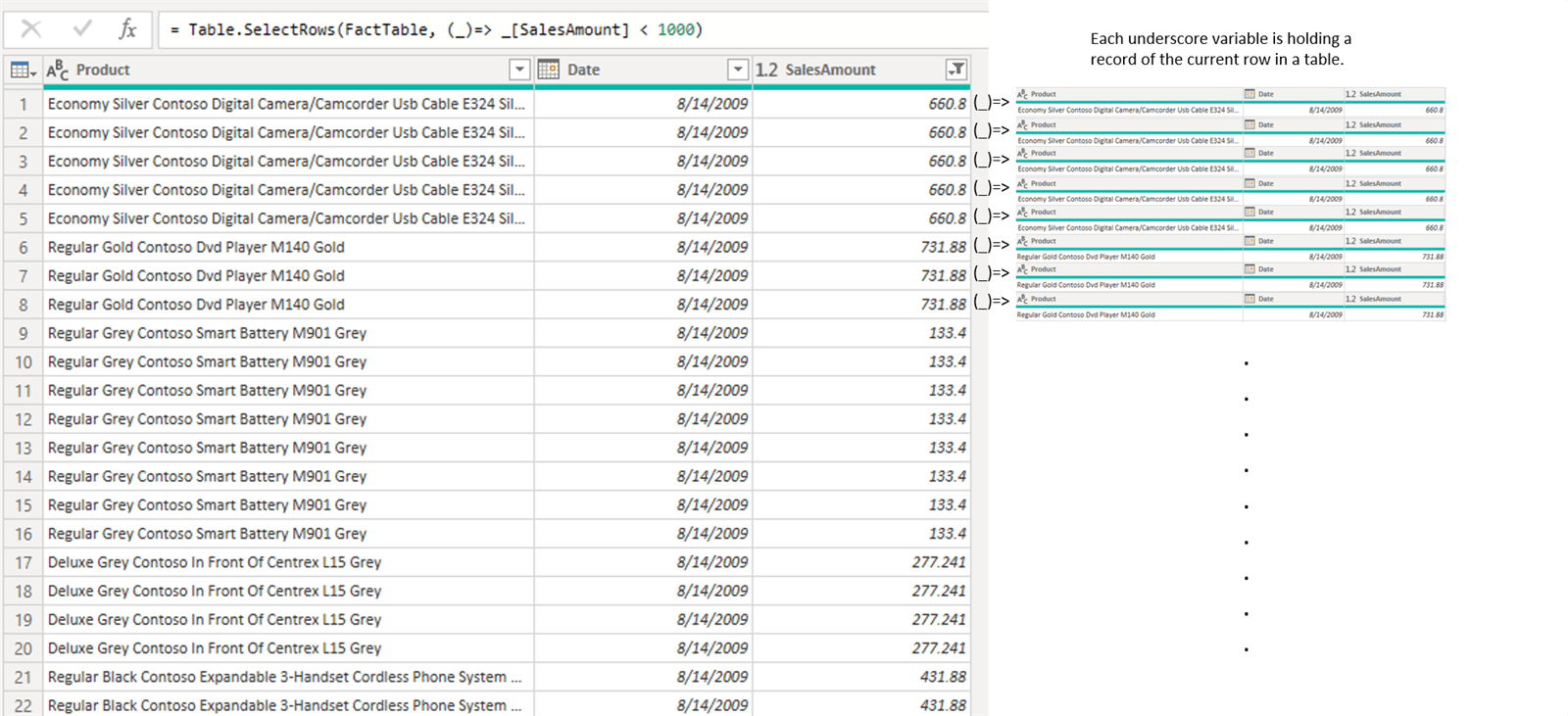
Each creates a “temporary” record type variable in which the underscore symbol represents the current row of the table iteration. After the variable containing the current row is created, it is then called from within the current iteration with the use of the underscore symbol followed by the name of the column that is being used as a condition. Because underscore is a default variable for each syntax, it can be omitted when calling a column name from the record. So the following syntax is also acceptable. = Table.SelectRows(FactTable, (_)=> [SalesAmount] < 1000)
Most of the time we will invoke iterations only in one environment (we discussed environments in the M part of the course), meaning only one table iteration in a step. In that case, the eachsugar syntax is completely acceptable and much easier to understand and use. The issue starts when we need to introduce another, nested row iteration.
In our example, we need to, after we start the iteration over the FactTable, for each row in the FactTable, introduce another iteration, this time over the Categoriestable. If we try to create such an expression using the eachkeyword, we will be out of luck.
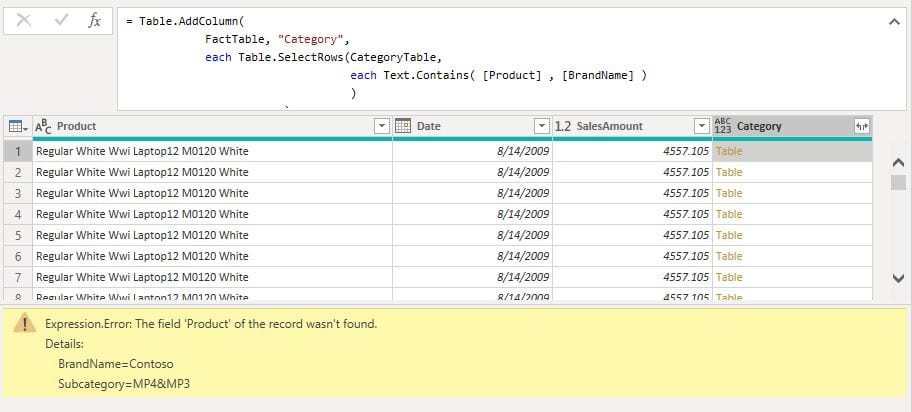
Table.AddColumn() and Table.SelectRows() are both “iterative” M functions, meaning they create row context iterations over the tables supplied as the first argument to the function.
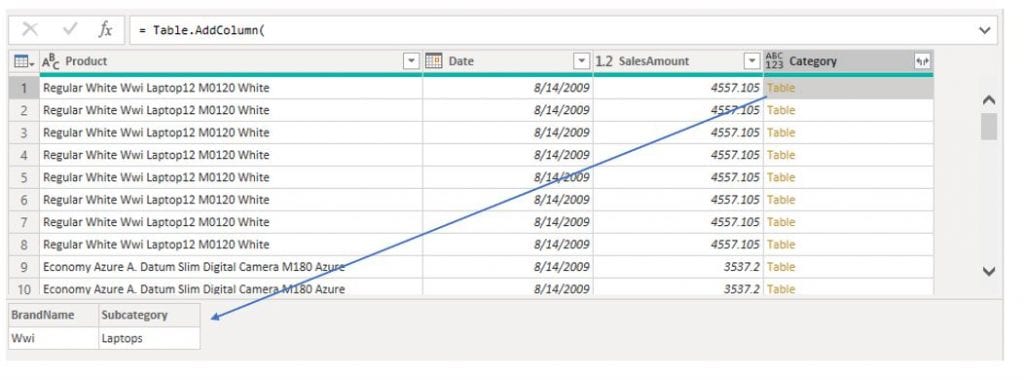
With the following M formula, we created a nested iteration. The outer iteration is introduced with Table.AddColumn() function and the inner one is introduced with Table.SelectRows(). Keyword each in the 3rd row is iterating over the sales table, and the inner each (4th row) is iterating over the Category table. The problem becomes evident in the Table.Contains() function, where we need to search the [BrandName] of the current inner iteration (which is a part of the Categories table), against the current product name of the outer iteration over the FactTable.
This becomes even more evident if we remove the sugar syntax!
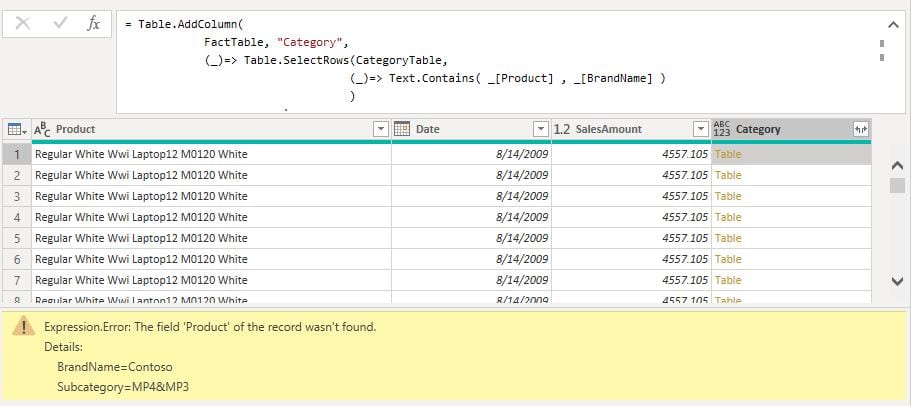
After the sugar syntax is removed, we can clearly see that now both [Product] and [BrandName] columns are trying to access the inner, category table record. Because of the underscore variable name conflict, the outer underscore, which is holding a record of the outer iteration, is not reachable from within the inner iteration. Therefore, the column [Product], which is the outer iteration record column, is non existing in the inner environment, producing an error as shown in the picture above.
Correct Approach to Nested Function Calls
Now let’s show the correct approach.
= Table.AddColumn(
FactTable, "Category",
(OuterRow)=> // introduced with Table.AddColumn function
Table.SelectRows(CategoryTable,
(InnerRow) => //Nested iteration introduced with Table.SelectRows function
Text.Contains( OuterRow[Product] , InnerRow[BrandName] )
)
)
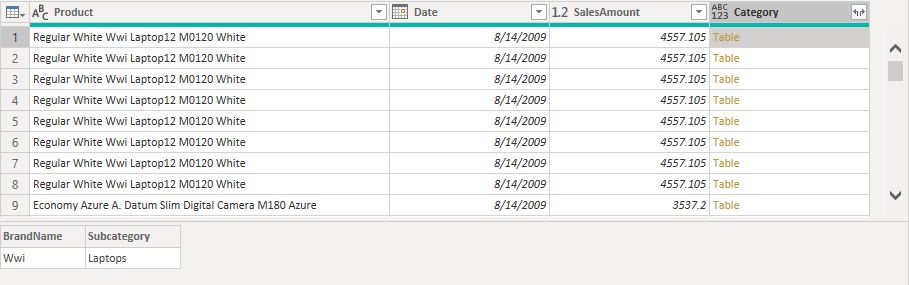
Even though underscore is a default variable holding a record of the current row iteration, you are allowed to supply any other name as a variable that will enter the function. In case we supply a different name than the default _, then we must always prefix that name before calling a column from the record.
This time, instead of writing eachfor the inner iteration, we created a function invoke with the InnerRow argument. This means that each row of the inner iteration will be bound to the InnerRow variable. In the condition part of the Text.Contains() we also bound the [BrandName] column to the InnerRow variable.
After we change the outer variable from default underscore to OuterRow, we are able to clearly see that the [Product] column is now bound to the current row of the outer record iteration created by Table.AddColumn() function, while the [BrandName] column is bound to the inner iteration of the Table.SelectRows() function.
Now there is no conflict in defining function argument names, so the outer environment variable (OuterRow) can be reached from within the inner iteration (inner environment).
This is extremely useful in case we need to introduce nested functions, but it also comes at the expense of performance. This is an extremely expensive operation, especially in case the inner table is big. This is also an excellent place to use Table.Buffer() function to load the inner context table into memory for a better execution time!
Using Table.Buffer() to provide better performance
The last part of this article is about the Table.Buffer() function. Nested iterations are very problematic in PowerQuery, since they have a huge impact on the query loading speed. If we were to load this query to the data model as is, it will take a couple of minutes to lead.
What we can do, and should do every time we have nested iterations, is to try to use Table.Buffer() function to push nested iteration into a memory, optimizing the performance. There are also List.Buffer() and Binary.Buffer() functions that work on the same principle. And what is the principle? It’s the principle of storing the table, list, or binary object in RAM, making it a stable reference isolated from external changes during evaluation. That means faster reads of data and faster performance.
In our case, it would be a good idea to push the category table to the memory by encapsulating it with a Table.Buffer() function. Following is the whole M code of the solution.
let
FactTable = Fact,
CategoryTable=Table.Buffer(Category),
SegmentColumn =
Table.AddColumn(
FactTable, "Category",
(OuterVariable)=>
Table.SelectRows(
CategoryTable, (InnerVariable) =>
Text.Contains( OuterVariable[Product] , InnerVariable[BrandName] )
)
)
in
SegmentColumn
Remember not to simply wrap the table inside of the Table.Buffer() when the table is already nested, because that will push the table to memory on each iteration, therefore we will experience no performance gain. Instead, you have to create a variable outside of the inner iteration and push it to the buffer function before starting the iteration. The table is now properly buffered and we can expect a huge performance boost from it.
Table.Buffer() use cases
In which situations can we benefit from Table.Buffer() function?
- When our table or list will be referenced multiple times (for example in List.Generate() function).
- Whenever using a recursive functions
- Before merging in certain occasions
- Before passing tables to functions
Be careful when using buffering with foldable sources since buffering breaks query folding which can result in worsen performance. Also, if your tables are big, think twice before buffering, because PowerQuery works with a “limited working set” meaning it limits the amount of data it stores in RAM and writes the remaining part on the hard drive.
Conclusion
Table.Buffer() is kind of a wild beast, you never know if it will produce a faster result, so it’s a bit of a trial and error. But when it does hit, it hits hard and you can expect to increase loading speed multiple times. So whenever you encounter a decrease in performance, try to utilize the buffering option.
Where Buffering is not a solution, or you should think twice before using it?
- If you use Table.Buffer() as a first step before referencing it from multiple queries. The data that is buffered cannot be shared between separate query executions – so the buffering happens multiple, once for each time the referenced query is evaluated.
- When you are working with foldable sources.
That’s all for this article! Hope you enjoyed reading it. In case you have any questions, please post them in the comment section!
Hi, Thank you for your blog, it is very useful. Could you please elaborate on : If you use Table.Buffer() as a first step before referencing it from multiple queries.could you please provide an example of such M code showing bad usage of Table.Buffer.
Very good article in expaling _ function and table.Buffer. Thanks for sharing your wisdome
Great Step by Step Blog, Made we understand many things
Great! Glad you found our blog useful!